Raising Exceptions
Home
Blog
Archive
Home
Photos
Photo Gallery (Raw)
Git
Local Git Serve
Github
Scripts and Dotfiles
Projects
BLT [2022-Present]
Github
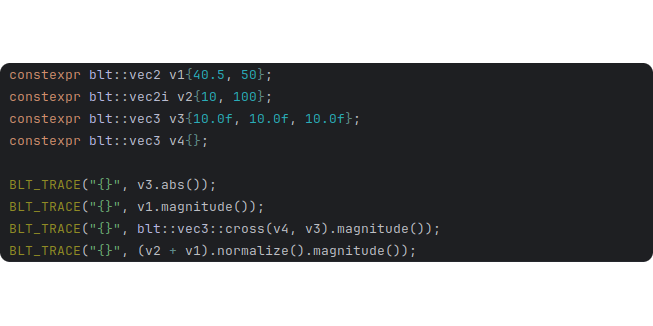
Vector Library
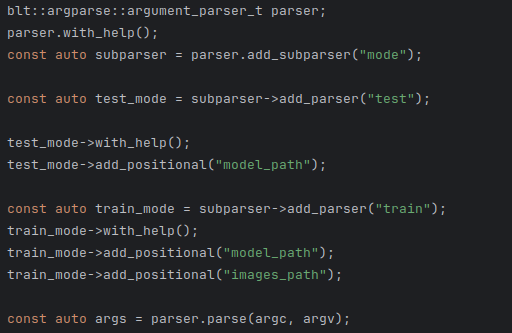
Argument Parser
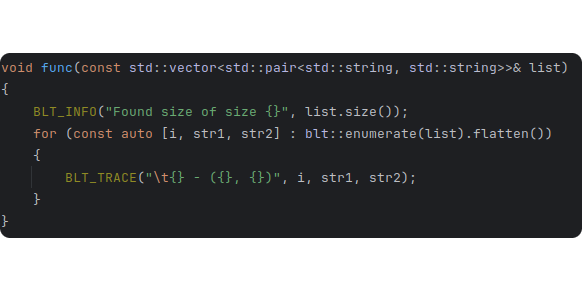
Iterator and Logging
Newsulizer [2025]
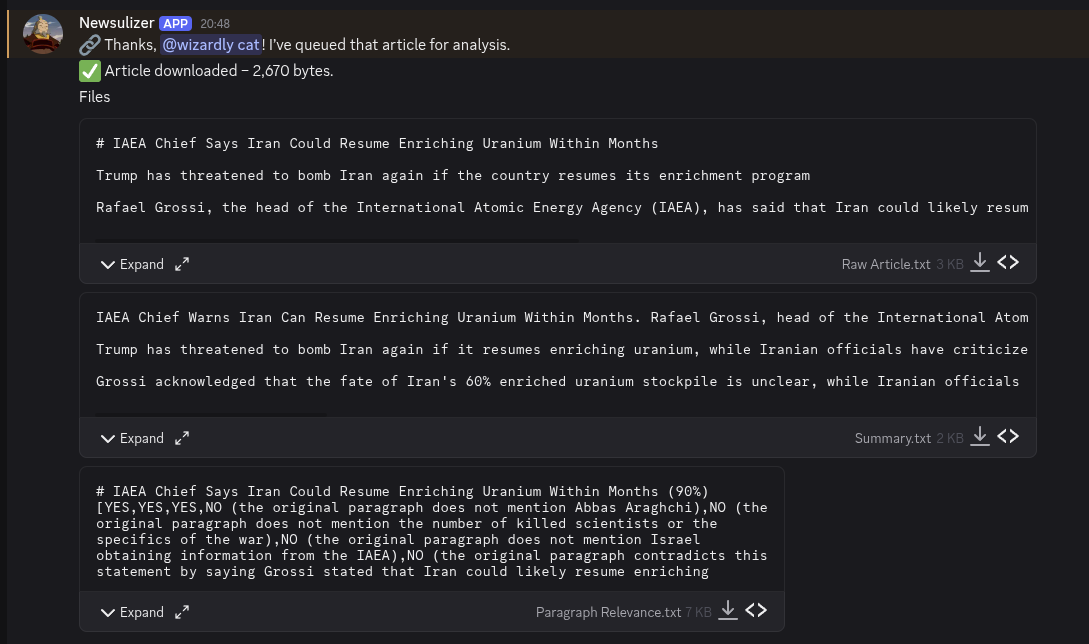
Discord bot / website which ranks paragraphs in news articles by relevance.
Created as an attempt at a new way type of AI summaries. See blog post for more information. [TODO]
Code / Git Repo
Link to website
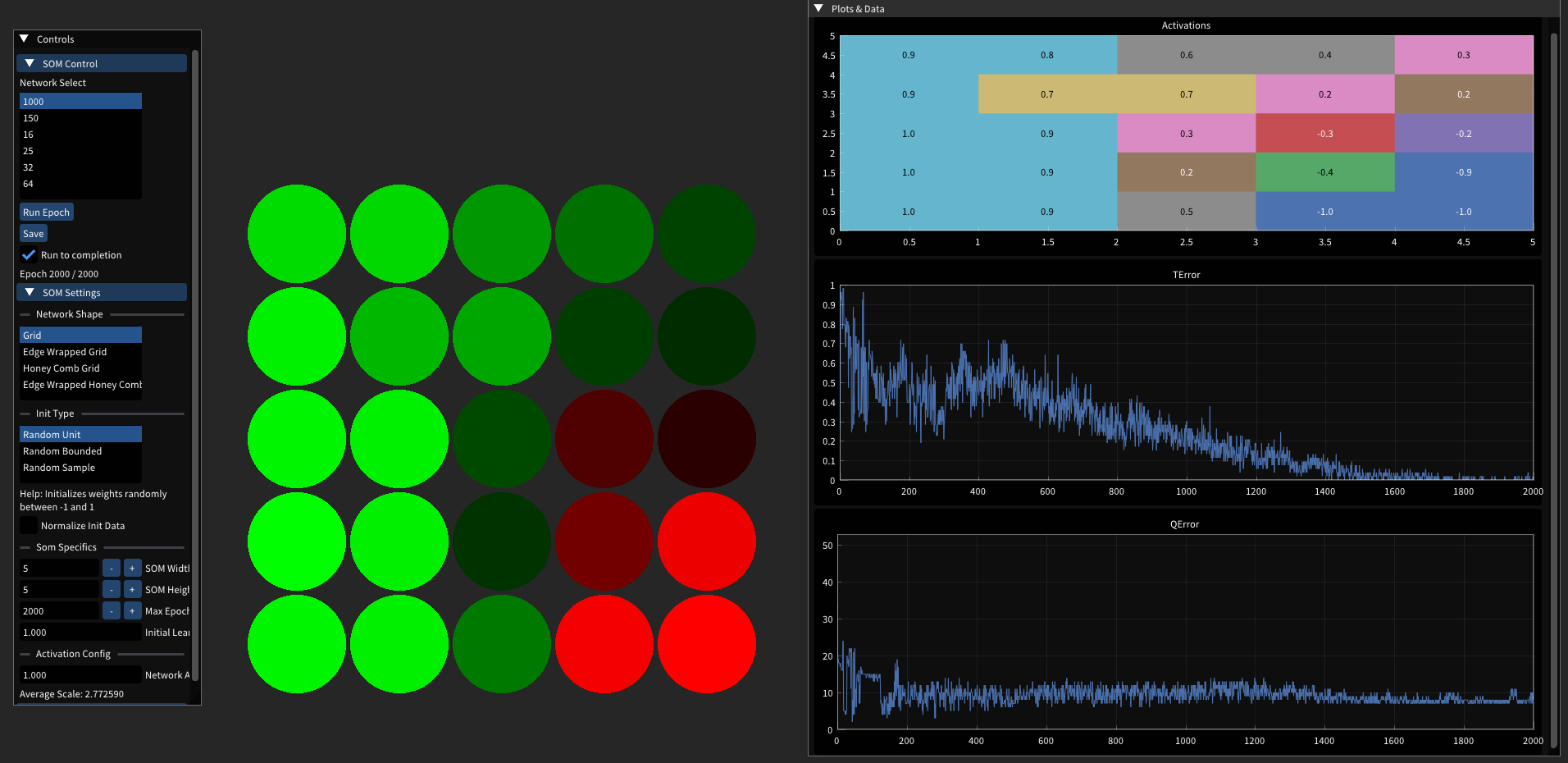
Self Organizing Maps On Motor Dataset [2024]
Web Playground Link
Code / Git Repo
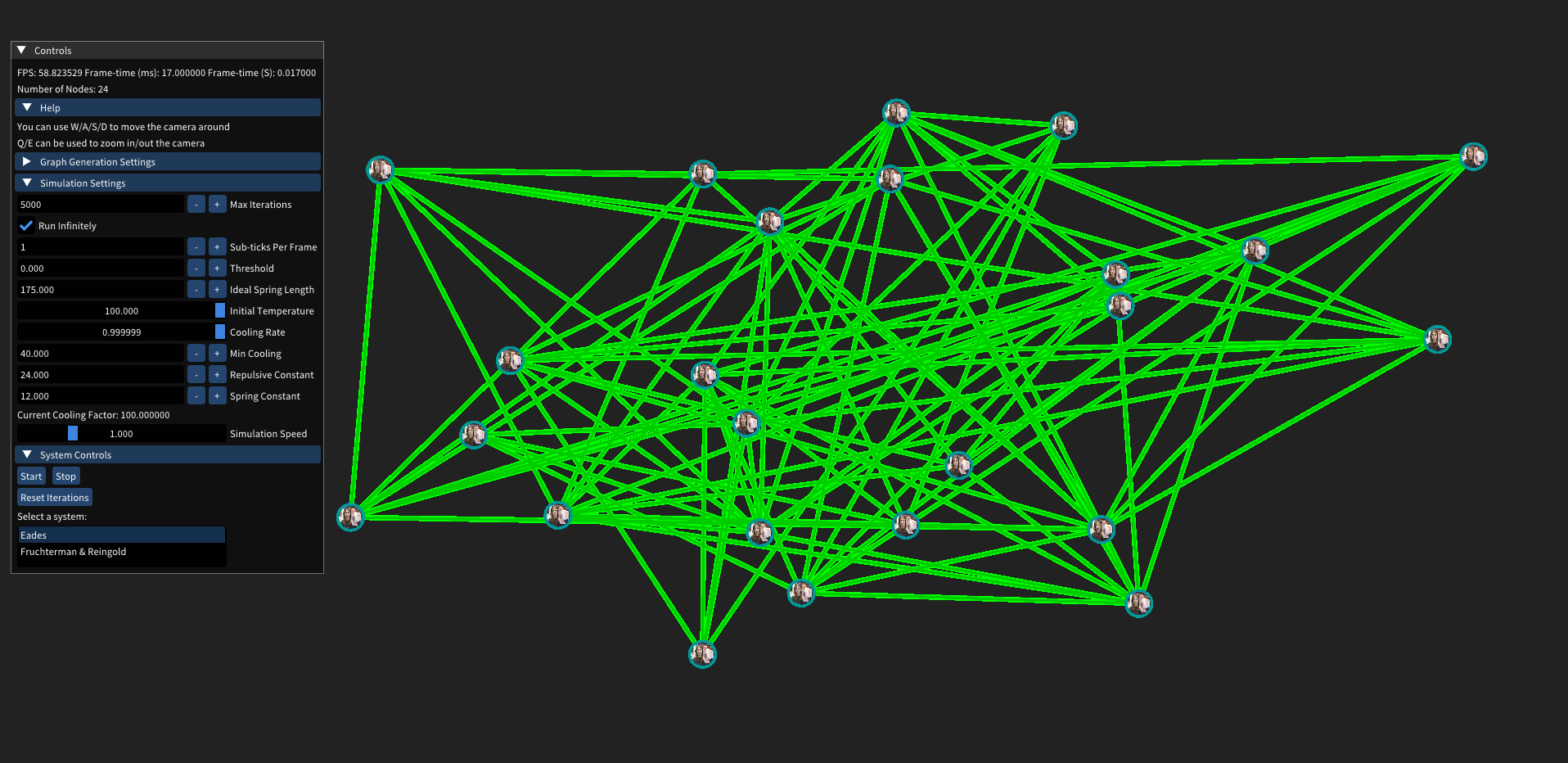
Force-Directed Graph Drawing [2024]
Web Playground Link
Code / Git Repo
Unfinished Projects
Brock CS Club Gamejam [2023]
Trapdoor [2021-2022] (Java / C++ Game Engine)